Threat Modeling has a Reputation Problem.
Ask most engineers what a threat model is and they'll describe something that happens in a conference room with a whiteboard, produces a PDF that nobody reads, and gets filed somewhere in the abyss forgotten to time and space itself.
They're not wrong about how it usually goes. But that's a process failure, not a method failure.
Done right, threat modeling is the highest-leverage security activity you can do early in a program. It forces you to look at the entire system simultaneously — before you get lost in the specifics of one tool, one pipeline, one vulnerability. And for a system like MedScribe-R-Us, where an AI model is making clinical decisions that get written into medical records, the consequences of missing a threat class aren't theoretical.
Phase 1(P1) produced six deliverables: three Data Flow Diagrams(DFDs) (L0, L1, L2 AI pipeline), a STRIDE threat register with 14 findings, an AI-specific threat model mapped to OWASP LLM Top 10 and MITRE ATLAS, and an attack surface document. All of it in Mermaid — code-based diagrams that render natively on GitHub without needing a diagramming tool.
This post walks through the thinking behind each one.Before we dive deep into this, I want to re-iterate a few things about me. I built the "Medscribe-R-Us" fictional AppSec pipeline as a case study for me and any one who wants to dive deeper into AppSec. The assumption here is that MedScribe has no security enabled, I would be the first AppSec person in the company, so what do I do? This case study answers that question. My background is in InfoSec, Hacking, and breaking things over the last 10+ years. Never been a builder type but looking for that to change. No matter your reasons for reading this, I hope that we can learn and grow together.
Starting with DFDs, Not Mitigations
The instinct when you do threat modeling is to jump to mitigations. Someone mentions "the AI pipeline" and immediately someone else says "we need prompt injection protection." That's true. But you don't yet know where the injection surface actually is, how many paths lead to it, or what the impact radius looks like.
Data Flow Diagrams slow you down in the right way.
I have built three levels for MedScribe-R-Us.
Level 0 — The Context Diagram
L0 treats the entire platform as a single black box. It answers one question: who talks to MedScribe-R-Us and what do they send?
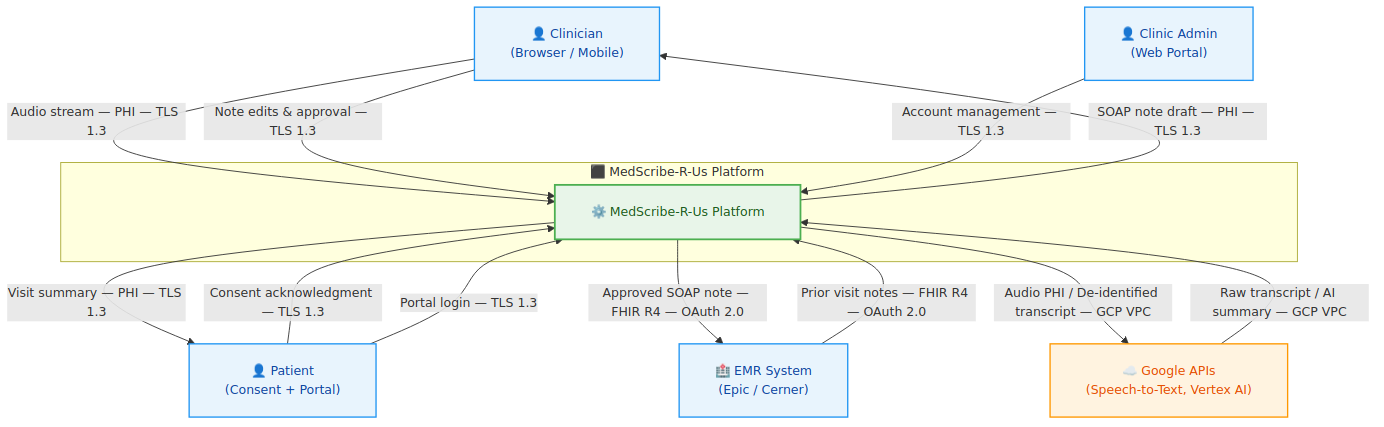
The external entities are the Clinician, the Patient, the Electric Medical Record (EMR) System (Epic/Cerner), Google APIs (Speech-to-Text and Vertex AI), and the Clinic Admin. At L0, the most important thing you learn isn't the data flows — it's the trust levels. The EMR is "semi-trusted" (authenticated via SMART on FHIR but not controlled by MedScribe). Google APIs are "third-party" (covered by BAA but not internal). The Clinician is "authenticated but low inherent trust" — credentials can be compromised.
Three observations that fall out immediately at L0:
- PHI crosses the internet boundary on every appointment recording: Audio streams from the clinician's browser to MedScribe over TLS 1.3. This is the highest-volume PHI flow in the system and the one most exposed to endpoint compromise.
- Google APIs are the only third-party that receives MedScribe data: Speech-to-Text gets raw audio (PHI). Vertex AI gets only de-identified transcripts. The PHI scrubbing layer is what enforces this separation — making it the highest-criticality control in the architecture before a single piece of STRIDE analysis has been done.
- The EMR integration is bidirectional: MedScribe reads prior notes from Epic/Cerner and writes approved SOAP notes back. Both directions carry PHI. Both directions require SMART on FHIR. Both directions are attack surfaces.
Level 1 — The Component Diagram
L1 decomposes the platform into 19 numbered data flows across all component services: Audio Ingestion, Transcription, PHI Scrubbing, AI Summarization, Output Validation, EMR Integration, the three portals, MongoDB Atlas, GCS, and Secret Manager.
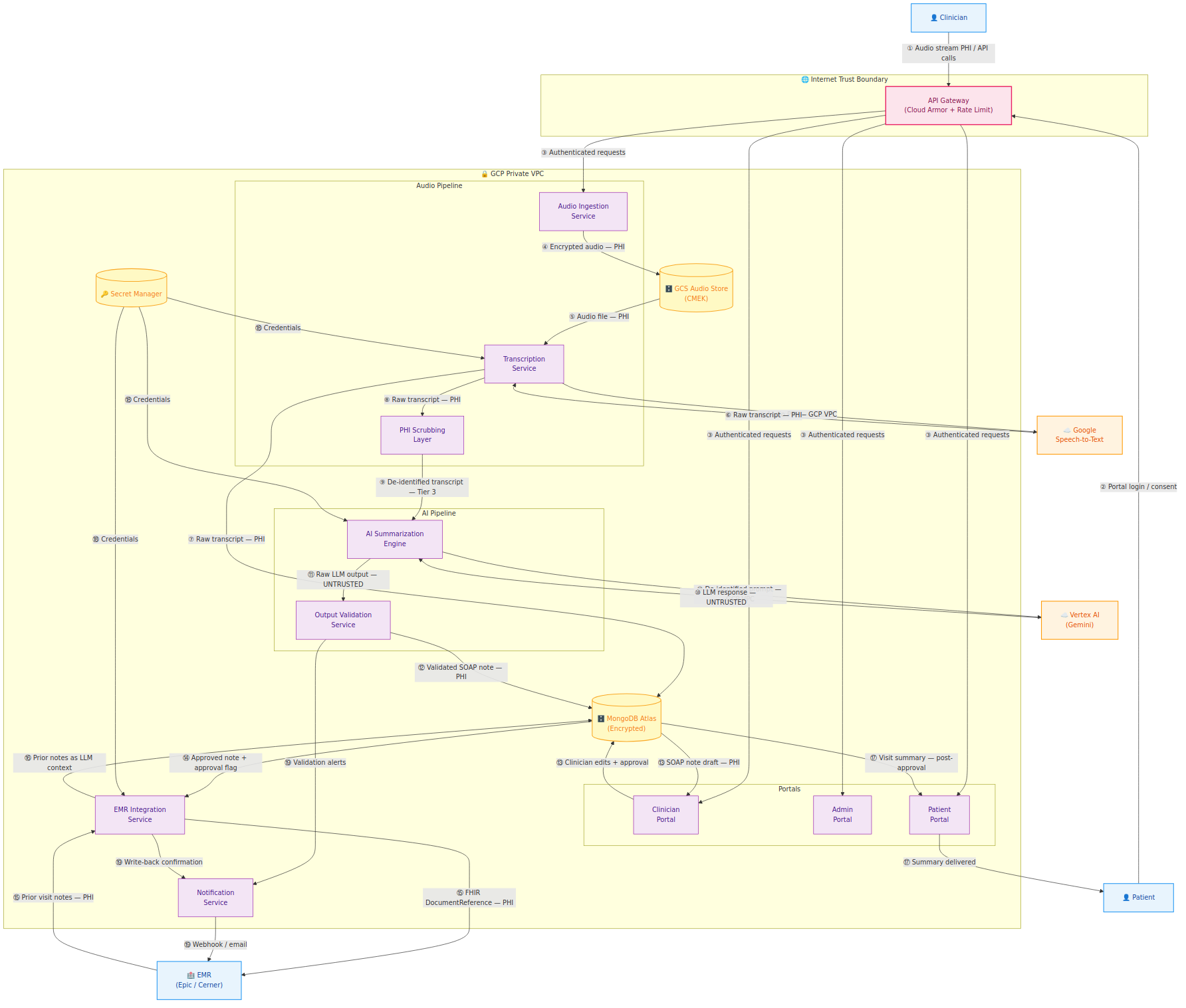
The numbered flows let you cross-reference directly into the STRIDE threat register — when a finding says "Flow ⑨", you can find it on this diagram immediately.
Four observations from L1 that generated the most significant threat findings:
- Flow ⑨ is the most critical control point: The transition from raw transcript (PHI) to de-identified transcript (Tier 3) happens here. Failure is silent — a missed PHI entity doesn't throw an error, it just travels into the Vertex AI API call.
- Flow ⑯ creates the indirect injection surface: Prior EMR notes are ingested from Epic/Cerner as LLM context. That data comes from a system MedScribe doesn't control. This became threat finding T-014 in the STRIDE register.
- Flow ⑭ must enforce the approval gate server-side: The approval state on a note must be validated by the EMR Integration Service reading from MongoDB — not trusted from the API request payload. Frontend-only enforcement is bypassable. This became T-009.
- Secret Manager (flow ⑱) is a single-compromise, everything-compromised scenario: It stores the Vertex AI API key, the MongoDB connection string, and the EMR OAuth client secret. This became T-013 (Critical).
Level 2 — The AI Pipeline Deep Dive
L2 zooms into the AI pipeline — flows ⑧ through ⑬ from L1 — decomposed into their internal steps. This is the diagram that doesn't exist in traditional web application threat modeling because traditional web applications don't have this component.
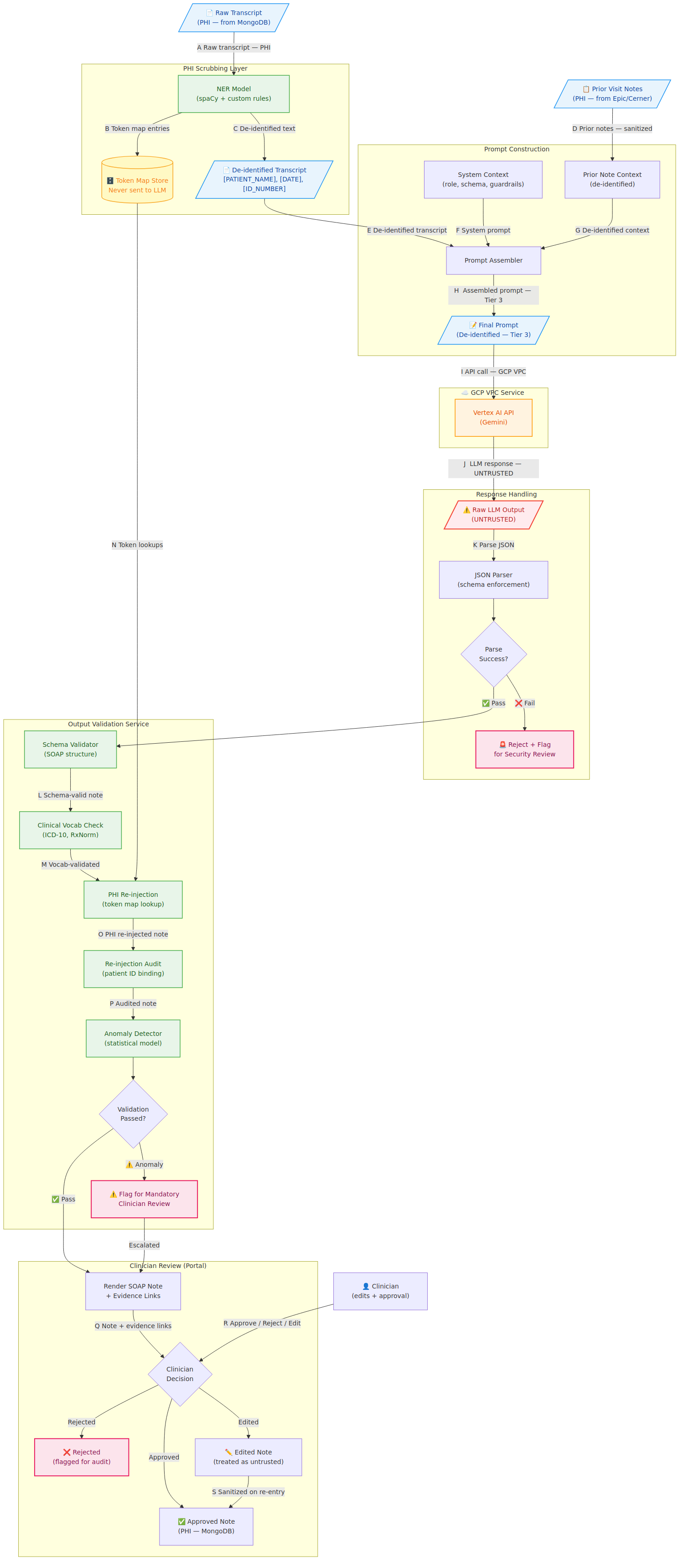
The ⚠️ Raw LLM Output (UNTRUSTED) node is the most important label in the entire diagram. Everything that returns from Vertex AI is treated as potentially adversarial until it clears every gate in the Output Validation Service. That's not paranoia — that's the correct security model for a system where the LLM output eventually gets written into a patient's permanent medical record.
Four critical security properties that L2 surfaces which L1 cannot:
- PHI scrubbing boundary — the NER model's false negative rate is a security KPI, not just a data quality metric. A scrubber that misses 2% of PHI entities means 2% of sessions send unmasked patient identifiers to Vertex AI.
- Untrusted LLM output — sandboxed JSON parsing, schema enforcement before any field is read downstream
- Prior note context as injection surface — Flow D is adversarially controllable by anyone with EMR write access to Epic/Cerner
- Clinician edit re-entry — edited note content is stored as literal text and sanitized before it ever re-enters an LLM context window
The STRIDE Threat Register
Running STRIDE across the L1 data flows produced 14 findings. The severity breakdown: 9 Critical, 3 High, 2 Medium, 0 Low.
Zero lows isn't a sign that we were too aggressive with severity — it's a reflection of the system. Every data flow in MedScribe-R-Us either carries PHI or controls access to PHI. HIPAA exposure is a severity multiplier, and in a healthcare AI company, it applies almost everywhere.
The most interesting findings:
**T-006 — PHI in Application Logs (Critical): One of the most common HIPAA violations in SaaS products, and one of the hardest to detect after the fact. Exception handlers that log request bodies, debug statements that include transcript content, error messages that echo user input — all potential PHI disclosure paths. Application logs are not subject to the same access controls as clinical data stores. They're often accessible to a much broader set of engineers, aggregated in third-party platforms, and retained on different schedules.
The mitigation isn't just a policy — it's a Semgrep rule built in P2 that blocks log calls passing variables whose names match a PHI pattern list. Policy without enforcement is a suggestion.
- T-009 — Clinician Approval Gate Bypass (Critical): The approval gate is the core safety control of the entire product. No AI-generated note reaches the EMR without clinician review. If approval state is enforced only in the Next.js frontend, a direct API call to the EMR Integration Service with a missing or forged approval flag bypasses it completely. The mitigation: approval state is set by the clinician action endpoint and stored in MongoDB with a write-protected field. The EMR Integration Service reads approval state from MongoDB directly — it doesn't trust the request payload.
- T-010 — FHIR Write-Back Patient Spoofing (Critical): Writing a SOAP note to the wrong patient's EMR record is a HIPAA breach and a patient safety incident simultaneously. The SMART on FHIR token scopes the write to a specific encounter, but if the
appointment_id→ patient binding is enforced only at the application layer, a logic error could result in clinical data landing in the wrong record. - T-013 — Secret Manager Credential Compromise (Critical): Losing Secret Manager access means losing everything simultaneously: Vertex AI API key, MongoDB connection string, and EMR OAuth client secret. The mitigation is least privilege per service — each Cloud Run service has a dedicated service account with access only to its specific secrets.
The AI Threat Model
Standard STRIDE covers the system well but wasn't designed for LLM-specific threats. The OWASP LLM Top 10 fills that gap — and all ten risks map to MedScribe-R-Us in some form.
- LLM01 — Prompt Injection (two surfaces): Direct injection via the transcript (clinician dictates instruction-like content that appears verbatim in the de-identified prompt) and indirect injection via prior EMR notes (adversarially crafted prior notes from Epic/Cerner fire in the LLM context). The indirect surface is harder to defend because the data comes from a third-party system MedScribe doesn't control.
- LLM06 — Sensitive Information Disclosure (three sub-scenarios): The scrubber gap scenario (PHI entity missed → verbatim in Vertex AI prompt), the context bleed scenario (PHI from one session appearing in another via token map logic error), and the model memorization scenario (future risk if fine-tuning on clinical data). These cross-reference T-007 and T-008 in the STRIDE register.
- LLM02 — Insecure Output Handling: The LLM's output is consumed by four downstream systems: Output Validation, MongoDB, the Clinician Portal renderer, and EMR Integration. If any of them treat LLM output as trusted before validation, the consequences range from XSS in the portal to malformed FHIR documents corrupting the patient's EMR. The L2 diagram makes this visible — UNTRUSTED is right there in the flow, not buried in a doc.
The MITRE ATLAS mapping adds a second taxonomy layer useful for teams already fluent in ATT&CK. AML.T0051 (LLM Prompt Injection), AML.T0054 (LLM Jailbreak), AML.T0057 (LLM Data Leakage), and AML.T0010 (ML Supply Chain Compromise) are the four most relevant techniques for MedScribe's current architecture.
The Attack Surface Document
The attack surface enumeration closes out P1. It's the document that scopes penetration testing engagements and DAST configuration — every internet-facing endpoint, internal service port, data store, and external integration, with the auth mechanism and PHI exposure status for each.
A few things worth calling out:
The WebSocket endpoint (/api/v1/audio/stream) is the most complex to secure. Authentication must persist across the WebSocket lifecycle, not just at the handshake. JWT expiry mid-session needs graceful handling — the session must be cleanly terminated, not left authenticated with an expired token.
The inbound webhook endpoint (/api/v1/webhooks/*) accepts data from EMR systems. HMAC signature validation must occur before any webhook payload is parsed — not after.
The Admin Portal serves two distinct user types with very different access scopes: Clinic Admin (tenant-scoped) and Platform Admin (cross-tenant). T-011 — horizontal privilege escalation — lives here.
What P1 Built and What P2 Uses
Fourteen threat findings. Three Mermaid DFDs. An OWASP LLM Top 10 + MITRE ATLAS mapping. A complete attack surface enumeration.
The thread from P1 into P2 is direct: T-006 (PHI in logs) drives a custom Semgrep rule. T-002 (API Gateway bypass via Cloud Run misconfiguration) drives a container security configuration check. T-011 (admin privilege escalation) drives an authenticated DAST test case. T-007 and T-008 (PHI scrubbing gaps, cross-patient token map) go to P4's AI security deep dive.
Threat modeling without tooling is a document. Tooling without a threat model is noise. P1 makes P2 intentional.
The DFDs, STRIDE register, AI threat model, and attack surface document are all in the repo under docs/threat-model/. Everything renders as Mermaid on GitHub — no diagramming tool required.
The full repo is on GitHub at https://github.com/LeSpookyHacker/medscribe-r-us-appsec/
All companies, patients, and clinical scenarios are fictional.
— LeSpookyHacker
Small Glossary of Acronyms
Since you are reading this, I am going to assume you know most general AppSec acronyms, so I will only be defining some medical specific ones, or new acronyms that some people may not know yet in the security field.
- ATLAS: Adversarial Threat Landscape for AI Systems (MITRE framework)
- BA: Business Associate (under HIPAA)
- CSF: Cybersecurity Framework (NIST) / Common Security Framework (HITRUST)
- EMR: Electronic Medical Record
- FHIR: Fast Healthcare Interoperability Resources (R4 refers to Release 4)
- HIPAA: Health Insurance Portability and Accountability Act
- HITECH: Health Information Technology for Economic and Clinical Health Act
- HITRUST: Health Information Trust Alliance
- MRN: Medical Record Number
- PHI: Protected Health Information
- PII: Personally Identifiable Information
- SOAP: Subjective, Objective, Assessment, and Plan (Medical clinical note format)
- SOC: System and Organization Controls
- STRIDE: Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, Elevation of Privilege (Threat modeling framework)
Join the Grimoire
Get notified when I publish new posts. No spam, unsubscribe anytime.